

 Project
Project Paper
PaperMotivation
MoE policies scale capacity, but continual RL can still make later tasks hard to learn.
- Plasticity loss: new gradients lose useful update directions.
- MoE gap: sparse experts can still collapse spectrally.
- SPHERE view: track plasticity via eNTK effective rank.
+133%
MetaWorld CRL success vs. unregularized Top-K MoE
+50%
HumanoidBench CRL success vs. unregularized Top-K MoE
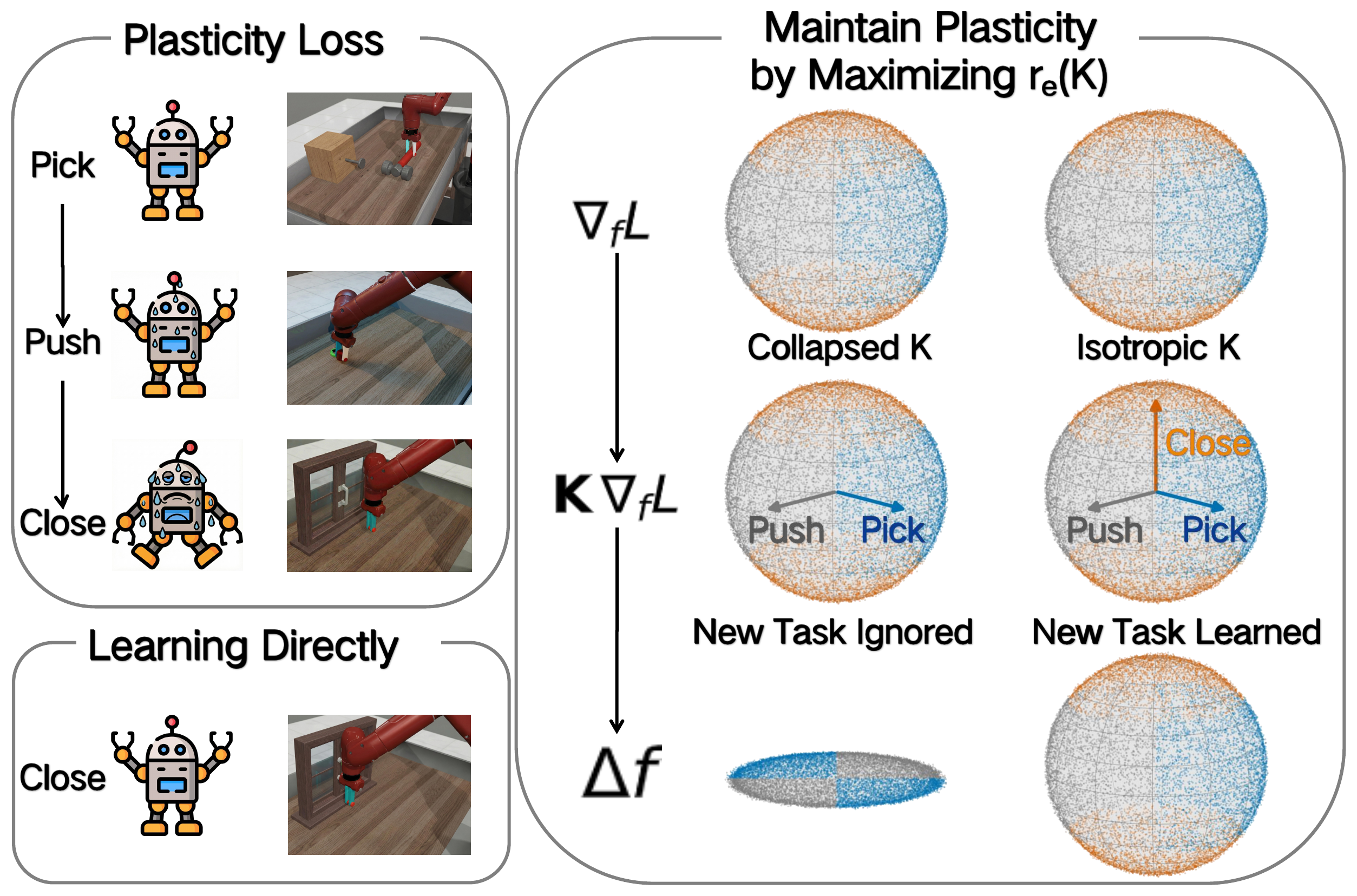
Core intuition. A collapsed eNTK spectrum filters gradients into a few update directions. A more isotropic spectrum lets new-task gradients move the policy more broadly.
Setup
Protocols. RL trains each task independently. CRL trains one agent through a task sequence, resuming from the previous task checkpoint.
Benchmarks. MetaWorld CW10 manipulation and HumanoidBench H1 control. Main metrics are final success and spectral plasticity $r_e(K)$.
Benchmarks. MetaWorld CW10 manipulation and HumanoidBench H1 control. Main metrics are final success and spectral plasticity $r_e(K)$.
Top-K MoEDS-MoEPPOCRL
Spectral Plasticity
The empirical NTK $K=JJ^\top$ maps output gradients to functional changes:
$\Delta f = -\eta\,K\nabla_f L$
If $K$ concentrates on a few eigen-directions, many gradient components are attenuated. We quantify update breadth by spectral-entropy effective rank:
$r_e(K)=\exp\!\left(-\sum_i p_i\log p_i\right)$, $p_i=\lambda_i/\sum_j\lambda_j$
Collapsed spectrum
low $r_e(K)$ · narrow updates
Isotropic spectrum
high $r_e(K)$ · broad updates
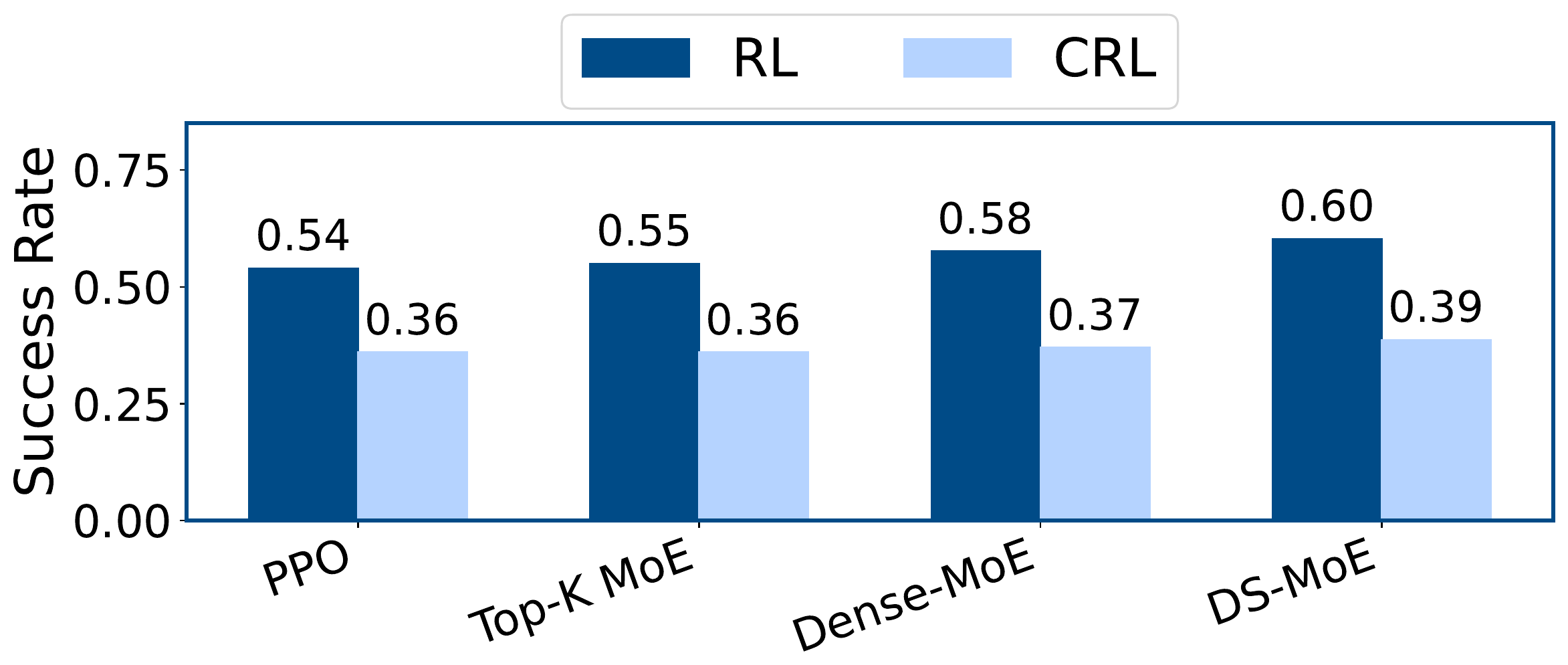
Plasticity loss is not only a dense-network issue. Continual training reduces success across dense PPO and multiple MoE architectures.
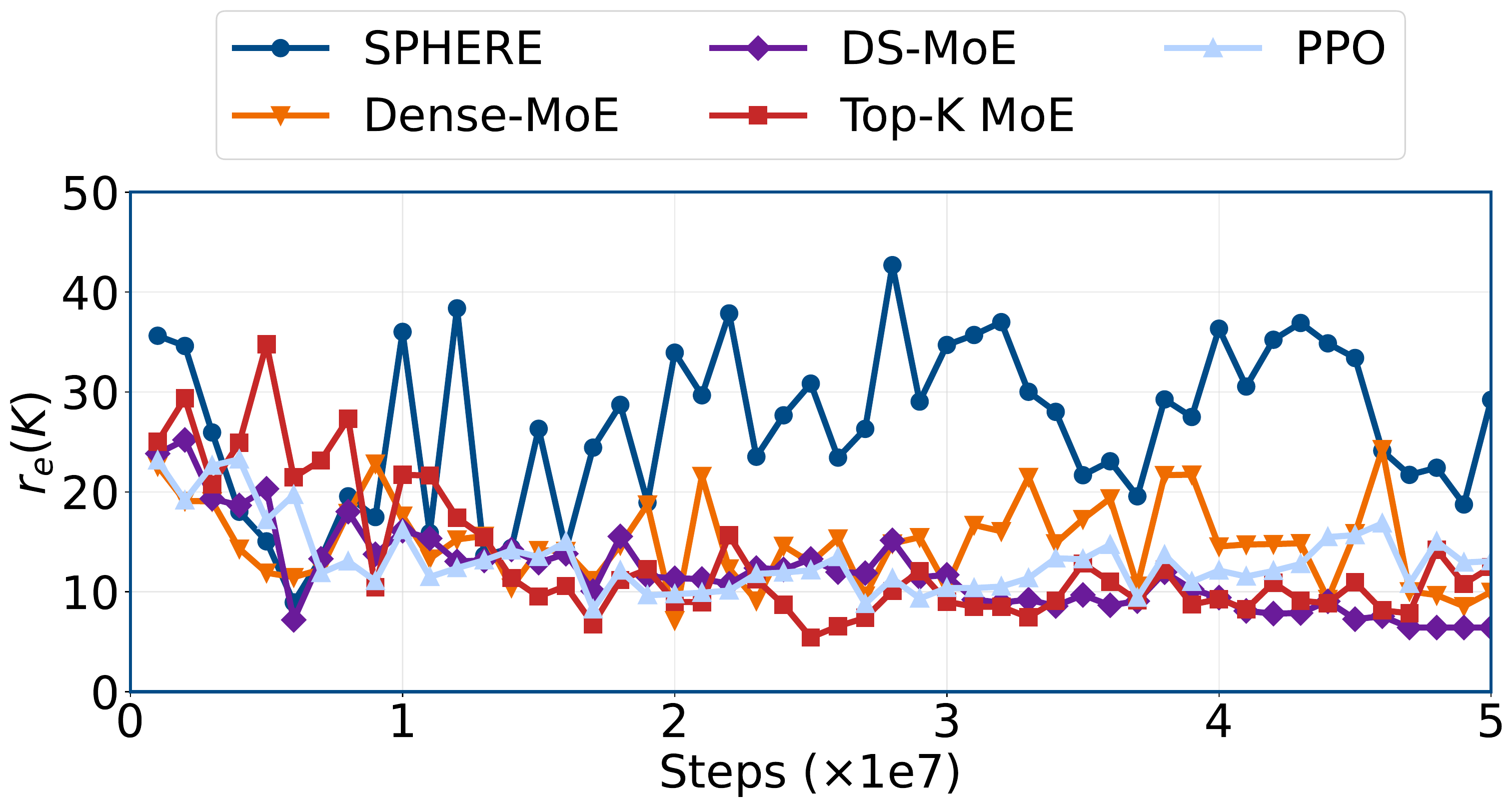
Spectral plasticity decays in baselines. SPHERE maintains higher $r_e(K)$ over HumanoidBench CRL while PPO, Top-K MoE, Dense-MoE, and DS-MoE drop toward lower-rank update geometry.
SPHERE Method
Directly forming $K$ is expensive. SPHERE acts on the routing-weighted expert feature Gram at the last hidden expert layer.
MoE forward
weighted expert features
→
feature Gram
$A^{exp}_{last}$
→
penalty
contract spectrum
$\mathcal L_{SPHERE}(A)=\left\|A-\frac{\operatorname{Tr}(A)}{m}I\right\|_F^2$
$\mathcal L = \mathcal L_{PPO}+\lambda^e\mathcal L_{SPHERE}(A^{exp}_{last})$
The penalty suppresses expert-feature anisotropy and improves a tractable spectral-plasticity proxy.
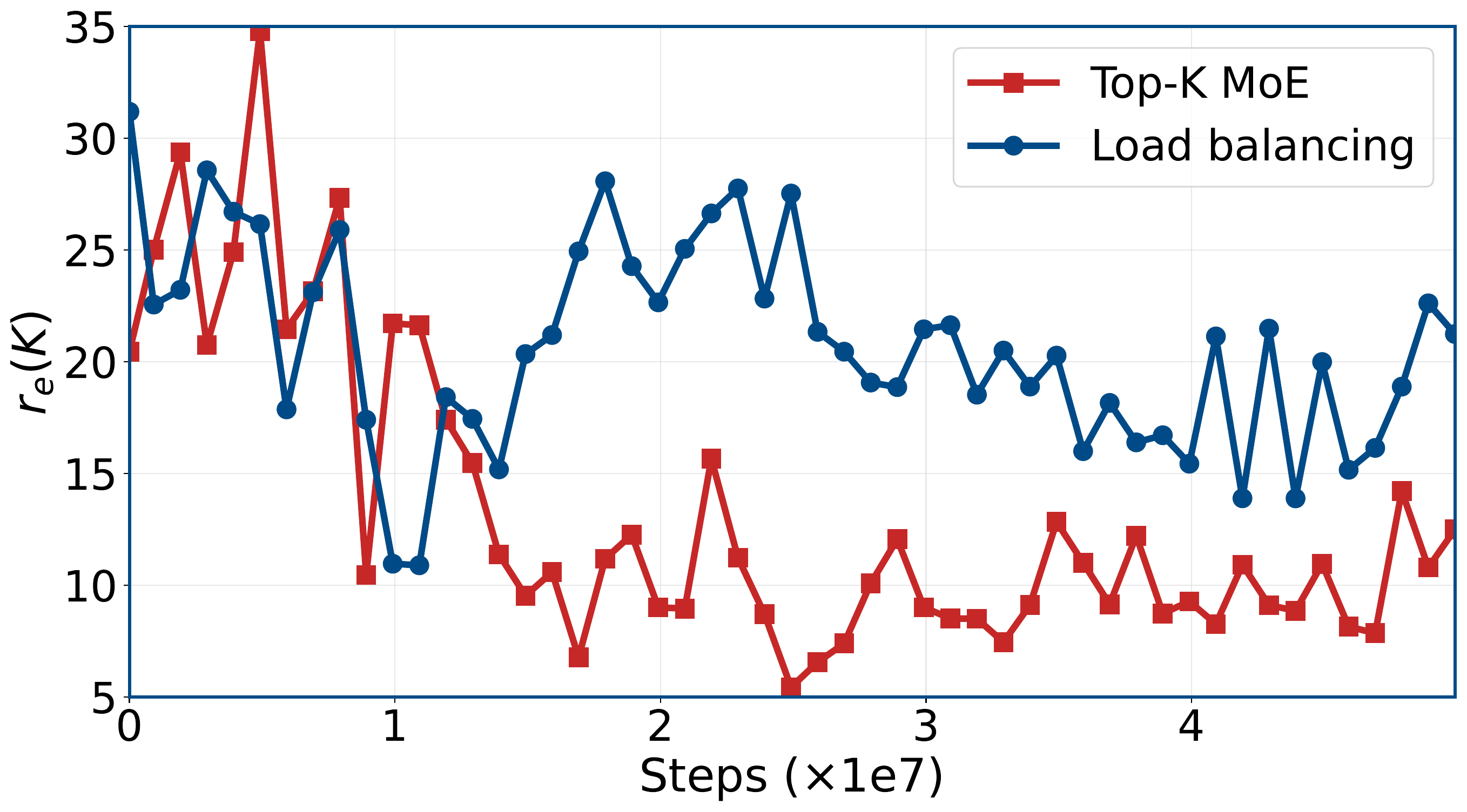
Not just load balancing. Expert-load balancing does not prevent the same spectral decay seen in Top-K MoE.
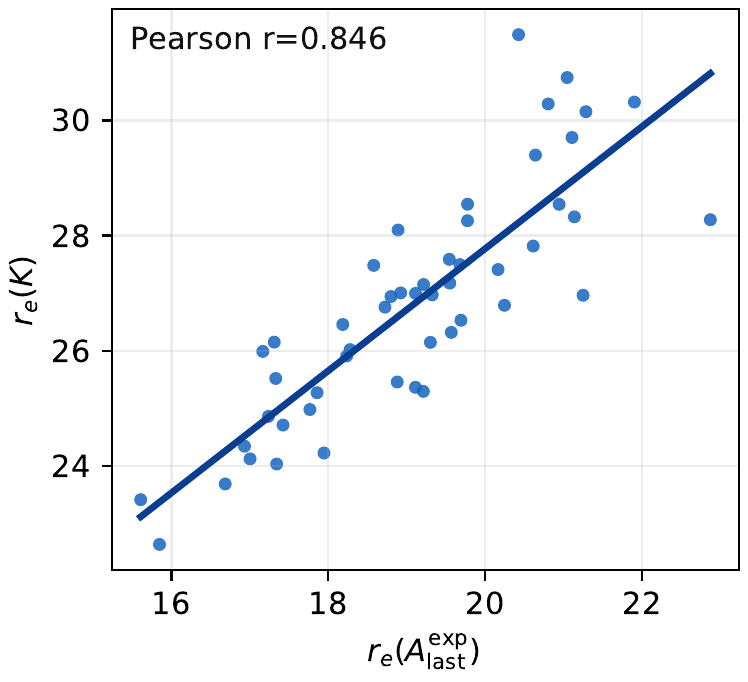
Proxy validation. Expert feature isotropy co-varies with $r_e(K)$ across rollout batches.
Design choices that matter
- Regularize the actor MoE.
- Use the last hidden expert layer.
- Concatenate weighted expert features to penalize cross-expert correlations.
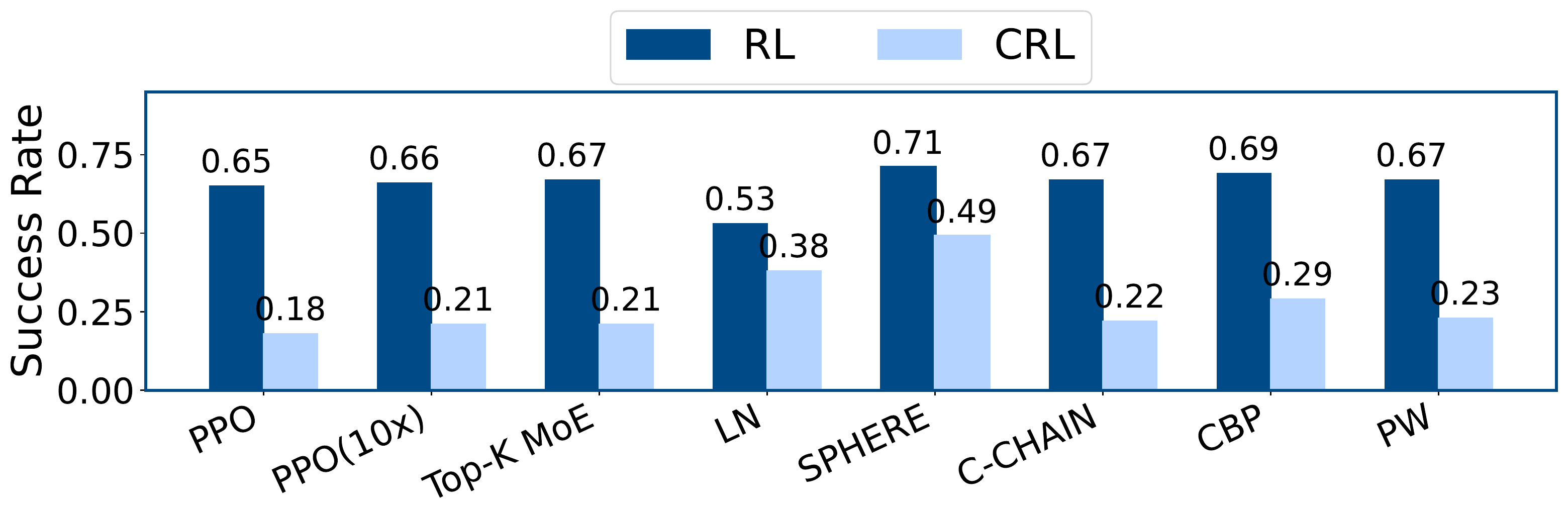
MetaWorld. Under CRL, SPHERE raises average success from 0.21 to 0.49 over Top-K MoE and narrows the RL–CRL gap.
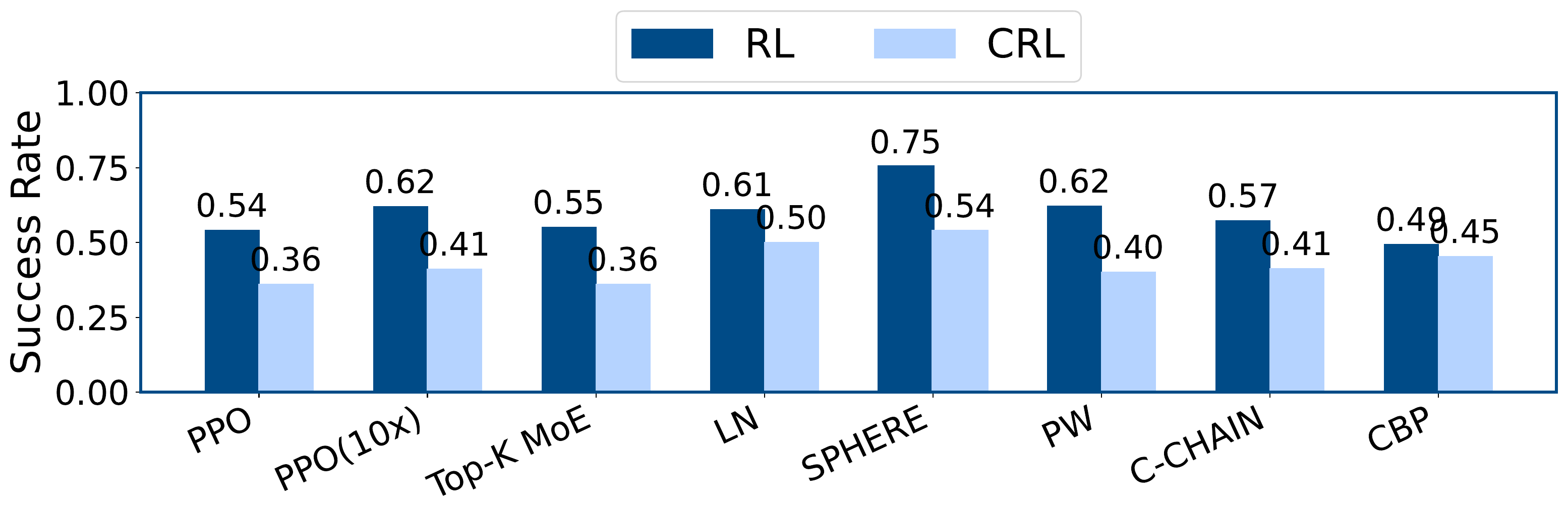
HumanoidBench. SPHERE improves average success over Top-K MoE under both RL and CRL, with a 50% CRL gain.
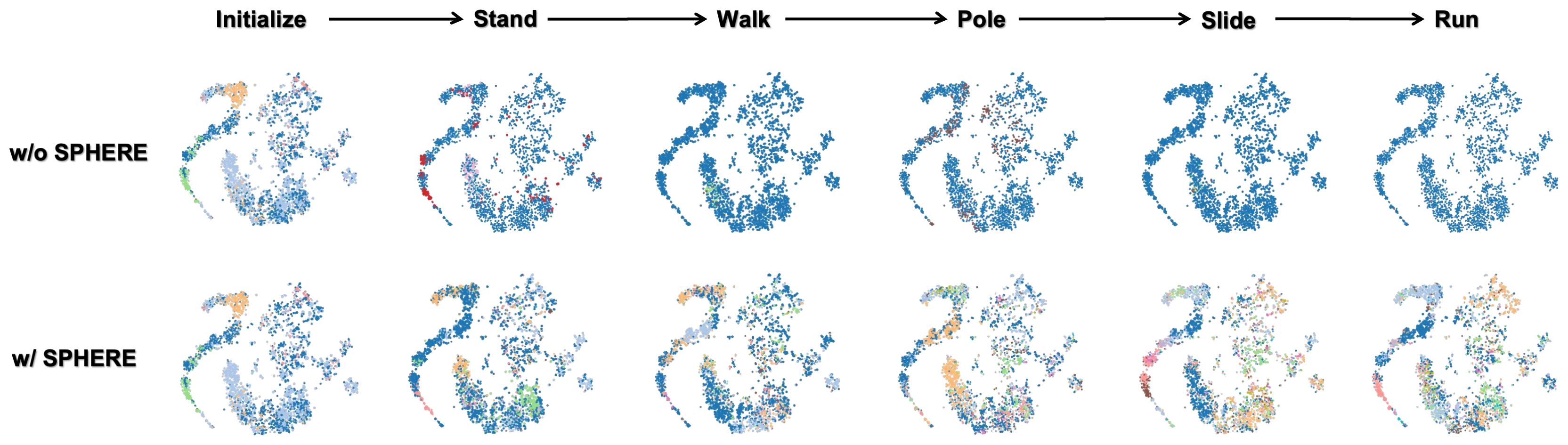
Qualitative evidence. Without SPHERE, states quickly concentrate on one dominant singular direction. With SPHERE, multiple components remain active across the continual task sequence.
Takeaways
- Spectral collapse explains one plasticity bottleneck: later gradients get fewer functional update directions.
- SPHERE is lightweight: add a feature-Gram Parseval penalty to PPO instead of forming the eNTK.
- Empirically robust: gains hold across MetaWorld and HumanoidBench, with routing, placement, spectral-baseline, and statistical checks.
Boundary: spectral plasticity is one specific eNTK-effective-rank view of plasticity loss, not a complete taxonomy of all plasticity mechanisms.